Für das tägliche Wordle-inspirierte Jahreszahlen-Quiz PastPuzzle habe ich kleines Bewertungssystem gebaut. Hier erkläre ich, wie es funktioniert und wo man es direkt benutzen kann.
Seit einigen Monaten spiele ich fast täglich eine Runde PastPuzzle. Das web-basierte, kostenlose kleine Quiz wurde von Tom Seidel in Anlehnung an Wordle entwickelt. Statt eines Wortes gilt es jedoch mit vier Rätselfragen eine historische Jahreszahl zu erraten. Zu jeder Frage, deren Antwort auf dasselbe Jahr verweist, gibt es im Anschluss eine weiterführende Quelle. Das Spiel ist mehr als ein Wordle-Klon: statt reiner Kombinatorik fließt auch historisches Wissen ein.


Im Anschluss an eine Runde gibt es eine Wordle-typische Auswertung, die sich auch auf Social Media teilen lässt. Tom hat einen guten Weg gefunden, die Abweichungen pro Jahr zu zeigen, ohne, dass das Ergebnis gespoilert wird:

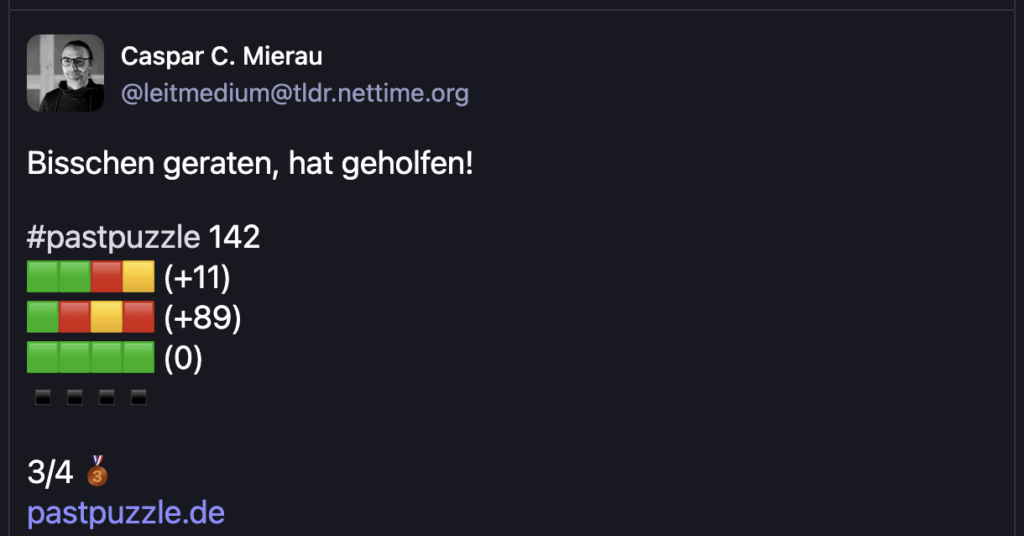
Auf Mastodon hat sich, zumindest in meiner Blase, das PastPuzzle zu einem kollektiven täglichen Spiel entwickelt und nicht selten werden danach Ergebnisse kommentiert und Lösungsstrategien diskutiert. Über eine Hashtagsuche (z.B. auf “meiner” Instanz oder auf der Hauptinstanz) findet man schnell andere Spielende.
Mir stellte sich die Frage, ob man Ergebnisse auch weiter automatisiert bewerten kann. So macht es natürlich einen Unterschied, wie viele Versuche man braucht, ob man das Ergebnis überhaupt errät und wie stark man vom Zielergebnis abweicht. Letzteres ist ein umstrittenes Thema, denn es gibt Ratestrategien, bei denen man wie bei Wordle versucht, durch geschicktes Platzieren von Zahlen das Ergebnis herauszubekommen, was aber zu teils großen Abweichungen vom Zieljahr führt.
Persönlich mag ich an PastPuzzle die Herausforderung, eher wenig mit den Jahreszahlen strategisch zu raten und lieber an den historischen Zahlen zu bleiben – wenn ich daran auch oft scheitere. Das macht für mich auch den Reiz geteilter Ergebnisse auf Social Media aus. Wenn hier jemand eher rät, sind die geteilten Ergebnisse weniger interessant, als wenn man sieht, wie die Person sich historisch „ranrät“.
Da ich schon immer mal „Spieleentwicklung“ ausprobieren wollte, habe ich den Versuch unternommen, einen kleinen Bewertungsalgorithmus zu entwerfen. Dieser Algorithmus ist „highly opinionated“. Er fasst die Annahme in Zahlen, dass Rätselergebnisse mit wenig Abweichungen besser sind, als welche, bei denen strategisch geraten wird. Wenn man zum Beispiel bereits weiß, dass die Jahreszahl mit 19… beginnt, aber dennoch 1234 rät, um mehr Zahlen probieren zu können, soll das zu einem schlechteres Ergebnis führen. Hier kann man anderer Meinung sein, aber wir wollen für diesen Versuch uns darauf einigen, dass das folgende Bewertungsschema zur Beurteilung genau dieser Eigenschaft entwickelt wurde.
Als Ausgangspunkt wollte ich mit dem Algorithmus folgende Eigenschaften abbilden:
- Je mehr Versuche jemand braucht, desto schlechter das Ergebnis.
- Das Ergebnis erraten ist besser, als es nicht zu erraten.
- Je stärker die Abweichung vom Ergebnis, desto schlechter das Ergebnis.
- Die Abweichung vom Ergebnis soll jedoch nicht übermäßig strapaziert werden. Jemand er 1000 Jahre daneben liegt, soll nicht hunderte Bewertungspunkte neben jemandem liegen, er 800 Jahre daneben liegt.
Die aus diesen Überlegungen abgeleitete Bewertungsformel lautet:
Score = 2 * (V - 1)
+ ln(D + 1)
+ (nicht_gelöst=1 oder gelöst=0) * (ln(D + 1) - 1)Final_Score = round(Score)
Zur Erklärung:
V ist die Anzahl der Versuche, also die Zahl 1 bis 4.
D ist die Summe der absoluten Abweichungen aller Versuche. Negative Abweichungen werden also wie positive Zahlen aufaddiert. Wer im ersten Versuch -10 und im zweiten +20 hat, bekommt eine Abweichung D von insgesamt 30 berechnet.
ln ist die Abkürzung für den natürlichen Logarithmus, auf den wir gleich noch kommen.
Gehen wir die Formel Zeile für Zeile durch.
2 * (V – 1): Hier nehmen wir die Anzahl der Versuche, subtrahieren 1 und multiplizieren das Ergebnis mit 2. Wer nur einen Versuch benötigt hat hier das Ergebnis 0, gefolgt von 2, 4 und 6.
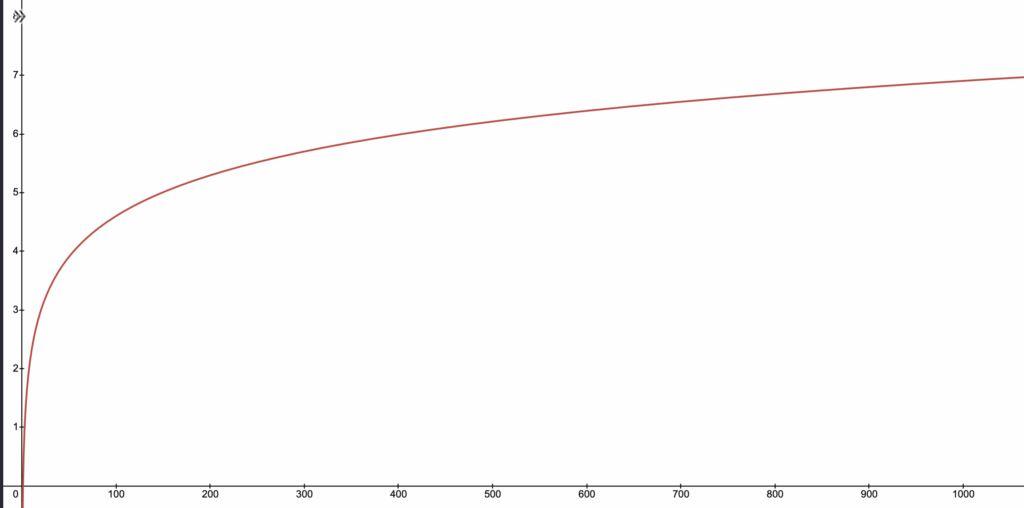
ln(D +1): hier muss ich etwas weiter ausholen. Um die Ergebnisse bei steigenden Abweichungen nicht aus dem Ruder laufen zu lassen, habe ich eine Funktion gesucht, die große Zahlen „staucht“. Die Logarithmus-Funktion ist so eine Funktion. Er staucht, wie in der folgenden Grafik zu sehen, Zahlen zwischen 1 und 1000 auf Ergebnisse zwischen 0 und 7, wobei der Anstieg zunächst stärker ist und dann immer weiter abflacht. Irgendwann ist es also egal, ob man noch ein paar hundert Jahre mehr daneben liegt.

Wir berechnen in unserem Fall den „natürlichen“ Logarithmus. Dieser basiert auf der eulerschen Zahl e, was an dieser Stelle nicht weiter relevant ist. Wer Interesse hat, kann sich hier dazu einnerden. Wenn Ihr aber einfach hinnehmt, wie die beschriebene Funktion ungefähr funktioniert, könnt Ihr das Rabbithole überspringen.

Da der Logarithmus von 1 exakt 0 ist, addieren wir zunächst zur Gesamtabweichung D eine 1. So verhindern wir, dass bei einem Treffer im ersten Versuch, was D=0 bedeutet, eine negative Zahl entsteht, denn bei einer Zahl kleiner 1 liefert der natürliche Logarithmus negative Zahlen. Wir wollen kurz ein paar Zahlenbeispiele bringen.
Wenn D = 0, ist das Ergebnis ln(0+1) = 0.
Wenn D = 5, ist das Ergebnis ln(5+1) = 1,79
Wenn D = 23, ist das Ergebnis ln(23+1) = 3,18
Wenn D = 142, ist das Ergebnis ln(142+1) = 4,96
Wenn D = 516, ist das Ergebnis ln(516+1) = 6,25
Man sieht, wie bei steigendem D das Ergebnis zwar weiter steigt, aber immer weniger. Es wird also „bestraft“, daneben zu liegen, aber nicht linear.
(nicht_gelöst) * (ln(D + 1) – 1) = nun wollen wir noch belohnen, ob man das Ergebnis rausbekommen hat und dabei noch einmal berücksichtigen, wie sehr man daneben lag. Wer viel rumrät und trotzdem das Ergebnis nicht rausbekommt, soll ein schlechteres Ergebnis bekommen, als jemand der die ganze Zeit recht nah am Ergebnis war.
Die variable „nicht_gelöst“ ist entweder 0 für gelöst oder 1 für nicht gelöst. Wenn das Ergebnis gelöst wurde, kommt in dieser Zeile also immer 0 raus und kann ignoriert werden. Die Formel ln(D + 1) kennen wir bereits. In diesem Fall wird jedoch noch 1 abgezogen, um nur geringe Abweichungen weniger zu bestrafen. Oben im Fall von 5 war das Ergebnis von ln(5+1) ja 1,79. Das wäre hier dann nur 0,79. Zugleich müssen wir den einen Fall berücksichtigen, dass gleich beim ersten Mal das Ergebnis erraten wird. Hier wäre ln(0 + 1) – 1 insgesamt -1. Die Ergebnisse sind dann:
Wenn D = 0 … kommt nicht vor, da dann gelöst wurde.
Wenn D = 5, ist das Ergebnis ln(5+1)-1 = 0,79
Wenn D = 23, ist das Ergebnis ln(23+1)-1 = 2,18
Wenn D = 142, ist das Ergebnis ln(142+1)-1 = 3,96
Wenn D = 516, ist das Ergebnis ln(516+1)-1 = 5,25
Im letzten Schritt der Formel werden die Ergebnisse der drei Berechnungen addiert und gerundet. Um nun eine Gesamtbewertung vorzunehmen, bietet sich zum Beispiel folgende Einstufung an. Ich habe sie mit vielen Spielergebnissen ausprobiert und sie funktioniert ganz gut:
Bewertungstabelle
| Rang | Kategorie | Emoji |
|---|---|---|
| 0 | Perfekt | 🏆 |
| 1–5 | Sehr gut | 🥇 |
| 6–10 | Gut | 🥈 |
| 11–15 | Durchmischt | 🥉 |
| 16–25 | Wild / Festgefahren | 🎲 |
| >25 | Verrannt | ❌ |
Um den Auswertungs-Algorithmus auch benutzbar zu machen, habe ich eine kleine Seite gebastelt, in die man ein PastPuzzle-Ergebnis pasten kann, und das Ergebnis berechnet wird. Ich bin kein Webentwickler und hoffe, das Formular und der Javascript-Code ist robust genug für alle Szenarien und entschuldige mich, dass es sicher nicht modernen Webstandards entspricht.
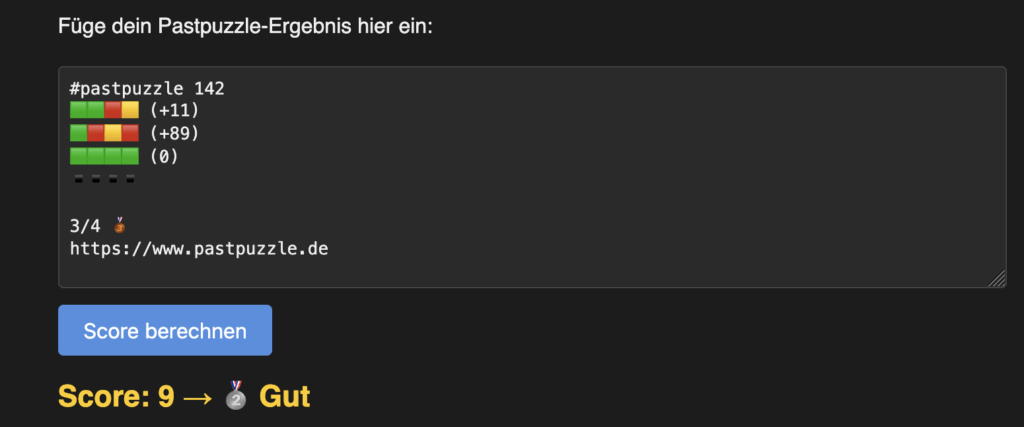
Mein heutiges Ergebnis berechnet ein “Gut” für ein erfolgreiches Raten in V = 3 Versuchen mit einer Abweichung von insgesammt D = 100:

Den Quelltext der Seite habe ich in einem Git-Repository abgelegt.(Weil wir hier ja auch gern über Digitale Souveränität, Safe Choice Bias und Alternativen sprechen, liegt das Repository bei CodeBerg statt GitHub). Gern kann das kleine Projekt verändert, verbessert, kommentiert werden.
Vielen Dank noch einmal an Tom Seidel für das wunderbare kleine, werbefreie Spiel, für das man übrigens auch spenden kann, um die technologische und redaktionelle Arbeit zu unterstützen.