

Seit über einem halben Jahr läuft der NSA-Skandal. Seit über einem halben Jahr veröffentlichen insbesondere der britische Guardian und die New York Times weitere Details aus den Snowden-Dokumenten. Zu der Veröffentlichungs-Strategie habe ich mich bereits hier und hier kritisch geäußert. Aktuell beschäftigt mich eine andere Frage: Warum interessieren die Snowden-Leaks zwar auf informativer Ebene, rufen zugleich aber keine statistisch relevanten Reaktionen hervor. Es ist von keinem ernsthaften Nutzer-Exodus zu lesen, es häufen sich keine Berge aussortierter Smartphones.+
Vielleicht ist ein Grund, dass wir den Skandal als aufregend skandalös empfinden und er uns bestens unterhält. Mehr aber nicht. Eine steile These? Werfen wir einen Blick auf die Nachrichten-Seiten, die an vorderster Front über die Leaks berichten, sich gegen Überwachung und Tracking stemmen und an der ein oder anderen Stelle auch schon mal einen Hauch von Anti-Amerikanismus durchblicken lassen…
FAZ
Erst gestern erschien in der FAZ der vielbeachtete “Aufruf der Schriftsteller“, in dem sich über 560 Autoren wie folgt äußern:
“Ein Mensch unter Beobachtung ist niemals frei; und eine Gesellschaft unter ständiger Beobachtung ist keine Demokratie mehr.”
Eine klare Forderung. Leider ist die Beobachtung von Benutzern ein so verlockend Effizienz-steigerndes Tool, dass beim Lesen des Artikels auf faz.net laut dem Browser-Plugin Ghostery immerhin 11 Tracking-Dienste eingesetzt werden – die die Daten zum großen Teil auch gleich in die USA transferieren (u.a. Doubleclick, Google Adsense/Analyics und Chartbeat):

Besonders lustig ist diese Tracker-Liste bei der FAZ, wenn man den FAZ-Service-Artikel “Wie wehre ich mich gegen Überwachung?” liest, in dem unter anderem die Frage aufgeworfen wird:
“Was wissen Google und Facebook denn über mich?”
Nun, in diesem Fall weiß Google zumindest, dass gerade der Artikel gelesen wird. Hätte man der Ehrlichkeit halber ja mal hinschreiben können. Statt dessen wird aber lieber mit dem Finger auf das Internet gezeigt – so als passiere es eben “dort” und nicht “hier und jetzt”:

Guardian
Diese offensichtliche Diskrepanz zwischen journalistischem Anspruch und Internet-Realität ist nicht nur Problem der FAZ. Auch der Guardian ist gut dabei – besser eigentlich. Ghostery meldet hier gleich 31 (in Worten: einundreißig) Tracker beim Lesen eines Artikels zu den Snowden-Leaks. Es sind so viele, dass man schon eher berichten müsste, welche nicht verwendet werden:
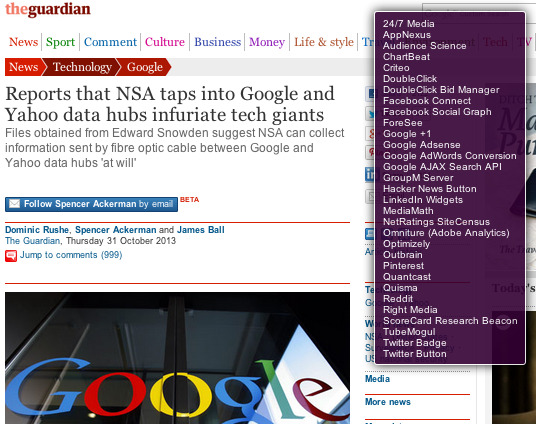
New York Times
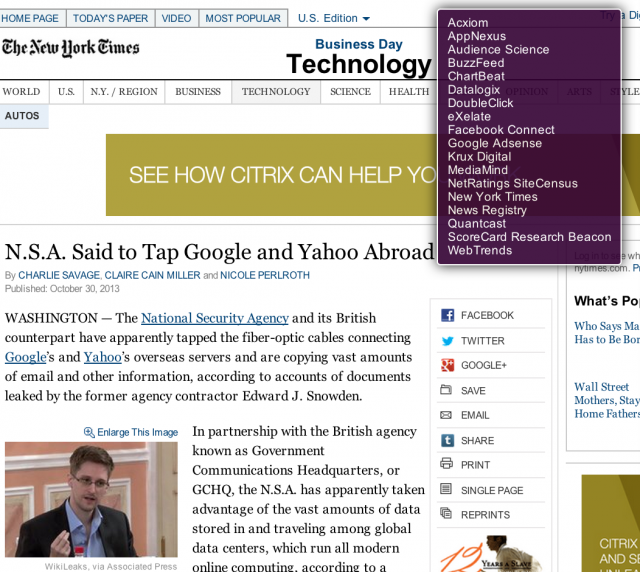
Auch die New York Times, die gemeinsam mit dem Guardian Leaks bearbeitet und veröffentlicht, reiht sich in die Liste nahtlos ein:
taz
Auch eher alternative Medienauftritte wie das der taz spielt in dem Spiel mit. Im Artikel “Googles Anti-Spähkampagne. Verlogen? Genau!” heißt es:
“Große Internetkonzerne wie Google oder Facebook starten eine Kampagne gegen Spionage. Selbst wollen sie auf das Datensammeln aber nicht verzichten.”
Zugleich bindet der Artikel Googles Werbe-Tracking-Netzwerk Doubleclick ein. Vielleicht ist es ja Haarspalterei – ich sehe hier einen Bruch, den ich so nur belächeln kann:

Die anderen? Auch… bis auf… Facebook?
Die Liste kann problemlos weitergeführt werden. Süddeutsche (24 Tracker), Spiegel Online (18 Tracker), ZEIT Online (14 Tracker), Welt (24 Tracker), BILD Online (24 Tracker) – es ist überall die gleiche Situation. Manchmal fragt man sich, ob hier Experimente gefahren werden, um möglichst verschiedene Tracking-Dienste gegeneinander laufen zu lassen. Moment – es gibt Ausnahmen. Zum Beispiel Facebook – hier muss mehrfach neugeladen werden, um einen (1!) externen Tracker wie Adition oder DoubleClick zu erwischen.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
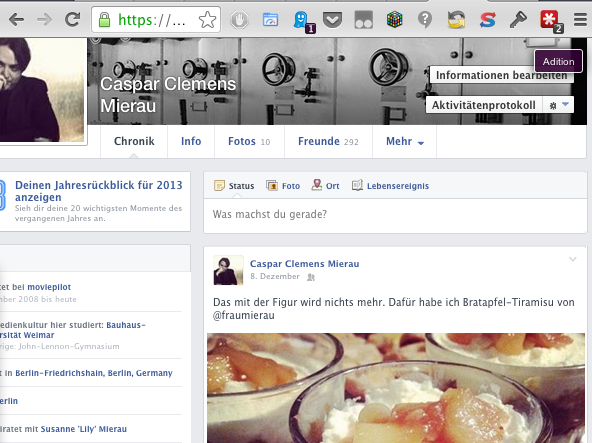
Natürlich ist das Aufführen von facebook.com als weitestgehend Tracker-freie Seite mehr als spitzfindig. Rein numerisch setzt die Seite aber weniger externe (und damit unerwartete) Dienste ein, als die Vorkämpfer für ein Überwachungs-freies Netz.
Fazit
Persönlich habe ich kein Problem mit Tracking-Diensten. Sie helfen bei der Analyse und Optimierung von Web-Auftritten. Deswegen echauffiere mich an dieser Stelle auch nicht über sie, um sie gleichzeitig stillschweigend einsetzen (diese Seite setzt Google Analytics, WordPress Stats, den Flattr-Button und ggfls. eingebettete Tweets ein). Die Diskrepanz zwischen Artikel-Inhalt und Realität auf journalistischen Angeboten erklärt Christoph Kappes wie folgt:
@leitmedium Verlag vs Redaktion, das ist überall dieselbe Situation.
— Christoph Kappes (@ChristophKappes) November 30, 2013
Damit hat er sicher Recht. Das Problem ist aber tiefgreifender. Die Logik des Netzes und die Logik des Kapitalismus scheinen einen steten Optimierungszwang auszuüben. Es ist uns zwar erlaubt, dies zu kritisieren – aber nur im getrackten und optimierten Rahmen. Immerhin sollen die Artikel ja von möglichst vielen Personen gelesen werden und zugleich auch Einnahmen generieren. Auch das kritisiere ich nicht. So ist das Netz, so ist unsere Wirtschaftslogik. Wir sollten nur damit aufhören, uns und anderen etwas vorzumachen.
Technischer Hinweis
Die Screenshots wurden in Chrome mithilfe des Ghostery-Plugins angefertigt. Die Zahlen sind nicht absolut, da sie von Aufruf zu Aufruf schwanken können (z.b. durch Ladefehler aber auch A/B-Tests der Betreiber). Wer den Test nachstellen möchte, sollte unbedingt Plugins wie Adblock Plus deaktivieren, da sie sonst das Ergebnis durch Vorfiltern verfälschen können.
Die Verlogenheit ist eklatant, das stimmt. Einerseits.
Andererseits kann ich bei Zeitungen aber auf die Printausgabe wechseln. Bei Staaten fällt das schon deutlich schwerer.
Die Darstellung von fb.com als trackerfrei ist nicht spitzfindig sondern Augenwischerei. Vielleicht kann es noch als ironischer Wink mit dem Zaunpfahl durchgehen. In jedem Fall verschleiert die Gegenüberstellung das grundlegende Problem: die absolute Ahnungslosigkeit der meisten User (zu denen übrigens auch die Redaktionen und die Verlagsmanager gehören).
Aber es zeichnet sich eine Lösung für das Problem ab. Immer mehr Nutzer verwenden Tools wie Ghostery (unter anderem . Den Anbietern der Trackingtools und der Werbenetzwerke ist dies bekannt und sie können dagegen auch nicht viel unternehmen, weil jede neue Technik früher oder später durch entsprechende Blocker verhindert werden. Letztendlich läuft es also auf ein massenhaftes Opt-Out hinaus, bzw. auf ein implizites Out-In. Damit sind wir dann eigentlich auch im Netz bei Panel-Analysen. Und die funktionieren ja auch gut im Offline, obwohl jedem Beteiligten klar ist, dass die Zahlen wenig mit der Realität zu tun haben. Die Werte sind in ihrer Ungenauigkeit aber vergleichbar. Und darum geht es doch bei der Preisfindung.
(Vielleicht wäre ja ein Screenshot dieser Seite hier auch noch interessant gewesen. Immerhin läuft hier mit Quantserve einer der größten Datensammler überhaupt.)
Sorry, aber wenn du tatsächlich das Erheben von Nutzungsstatistiken für Webdienste und systematisches Ausspähen und vor allem Kombinieren tatsächlich privater Daten bis hin zu privater Kommunikation in einen Topf wirfst machst du den selben Fehler wie Verlage, die Google als Buhmann darstellen, aber selbst Googleanalytics nutzen. Das, was die NSA und auch “unsere” Geheimdienste tun ist was völlig anderes als mal eben ein paar Trackingscripte auf einer Website laufen zu lassen. Letztere kann man ja auch ausschalten/blockieren, ohne großen Aufwand. Das Abschöpfen deiner Telefonate, die über eine Glasfaser laufen, kannst du nicht verhindern. Stichwort ist: informationelle Selbstbestimmung. Wenn ich nicht einmal mehr weiß, welcher Staat bei mir wo mitliest und hört (und mit welchen anderen Informationen, die er sich von überall her beschafft, er das alles verknüpft) kann ich mich nicht mehr wehren. Da nützt mir dann auch verschlüsselte Mail (was man als Nicht-Nerd erst mal hinbekommen muss, das “no-Script”-Plugin ist dagegen Pipifax, das bekommen auch “Normaluser” mit nur rudimentärem Interesse und wenig Aufwand hin) nichts mehr, wenn die Meta-Daten trotzdem gesammelt werden. Und Telefongespräche verschlüsseln dürfte dann endgültig nur noch für “Profis” machbar sein. Ich weiß nicht, ob dieses In-einen-Topf-werfen das eine Verharmlost oder das andere hysterisiert – so oder so tut beides beiden Themenfeldern nicht gut.
Die taz hat zu den Tracking-Diensten auf ihrer Seite schon vor einer Weile mal was geschrieben: http://blogs.taz.de/hausblog/2013/07/16/datentracking-auf-taz-de-ganz-schoen-vertrackt/
Hm. Natürlich ist es grenzwertig wie vieler “externer” Dienste sich solche Medien bedienen. Und mit Sicherheit kann niemand genau sagen, wo die Daten, die solche embedded services, letztendlich landen. Sorgen machen ist also ausdrücklich erlaubt.
Andererseits sollte man nicht verschweigen, dass Dienste wie flattr, G+ oder Facebook Connect ihre Berechtigung jenseits vom stoischen Sammeln von Daten haben und einen Sinn verfolgen, der es notwendig macht, zu wissen, dass jemand gerade den Artikel liest. Solche Dienste und Angebote selbst zu entwickeln und zu betreuen wäre für jeden Verlag ein massiver Overhead (zumal ich den Redakteuren fast jegliches Programmiererfahrung abspreche) und MUSS demzufolge von externen Betreibern verwendet werden. Und zwar von dem, der das beste Produkt anbietet. Meines Erachtens nach Zufall, dass all “das Zeug” aus den USA kommt.
Es ist nicht alles Gold, was glänzt, klar. Genauso wenig ist aber alles Sch…, was stinkt 😉 An unsere Daten kämen die mit Sicherheit auch ohne ihre Plugins.
Es gibt da einen wesentlichen Unterschied, der in der aktuellen Debatte zu kurz kommt:
private Unternehmen erheben Daten im Rahmen der Gesetze und halten sich an die Regeln des Datenschutzes.
Einige Geheimdienste erheben weiter gehende Daten, brechen absichtlich Gesetze und überschreiten die von ihren Regierungen gegebenen Regeln.
Es sind die NSA und GCHQ, die auf die Abschaffung der Demokratie hinarbeiten und nicht Werbung treibende Unternehmen.
Abgesehen davon, dass der Vergleich zwischen Tracking und NSA hinkt, trackt FB schliesslich auf jeder Webseite mit “Like”-Button mit. Da benötigt FB selbst kein Tracking mehr.
> Andererseits sollte man nicht verschweigen, dass Dienste wie flattr, G+ oder Facebook Connect ihre Berechtigung jenseits vom stoischen Sammeln von Daten haben und einen Sinn verfolgen, der es notwendig macht, zu wissen, dass jemand gerade den Artikel liest.
Etwas gutmeinend kann man sogar sagen, alle Dienste haben Ihre Berechtigung. Das Netz/HTTP ist so angelegt, dass eine Verfolgung der Ladevorgänge eher schwierig ist. Es gibt allerdings reichlich Gründe, Zugriffe zu messen: Werbepartner wollen „Beweise“ für Zugriffszahlen, die Verwerterindustrie ebenfalls (Zählpixel), das Marketing braucht auch Meßwerte um Statistiken und Metriken aufstellen zu können und Ihre Strategie zu bestimmen.
Dazu kommen allerlei technische Aspekte: Inhalte werden auf separaten Medienplattformen gehostet, weil man bspw. gar keine eigenen Streamserver betreiben kann, Zugriffe auf verschiedene Server steigern die Geschwindigkeit, Scripte werden über CDN oder Clouddienste bezogen, Cookies unterliegen einer Domainprüfung…
Wie gewaltig diese Entwicklung ist, sieht jeder, der sich mal ein entsprechendes Filterplugin installiert. Leider sind technische Vorgaben und Datenschutzbegehren in weiten Teilen kaum vereinbar.
Warum sich niemand aufregt? Weil bislang noch keine praktischen Folgen aus der Datensammelei entstehen. Solange es sich “nur” um abstrakte Werte handelt bleibt es ein intellektuelles Problem.
Wenn aber die ersten individuellen Versicherungsprämien in die Höhe gehen, weil man durch “falschen” Musikkonsum zum Hochrisiko geworden ist etc. wird sich die Sicht auf Datensamelei mit Sicherheit verändern.
Ich habe ebenfalls nichts dagegen, wenn Websites Nutzeverhalten profilieren um daraus ggf. bessere Dienste anbieten zu können. Ich finde allerdings, daß dies transparent geschehen muß und dem Einzelnen die Möglichkeit gegeben werden sollte sich in dieser Gleichung anders zu positionieren. Technisch ja überhaupt kein wirkliches Problem. Ghostery? Eine feine Sache, aber nicht wirklich nutzerfreundlich und verbraucherfreundlich. Das muß es aber sein.
Ist aber schon klar, das Facebook nur deshalb scheinbar frei von Tracking ist, weil es eine homogene, geschlossene Plattform ist? Wer mal die Beschränkungen erlebt hat, mit denen App-Entwickler für die Plattform leben müssen oder um den filigranen Zuschnitt der Zielgruppe für die man Werbung schalten möchte müsste wissen, das Facebook sehr wohl Tracking betreibt, es allerdings nicht nötig hat das an Dritte auszulagern. Dahingehend haben Verlage ja oft früh ihre Anzeigenabteilungen ausgegliedert oder gleich den Vertrieb gleich abgegeben.
Noch was: Spione kann man verhaften, solche diplomatischer Immunität ausweisen, aber worauf sich die ganze Verteidigung der Nichtstuer in der NSA-Affäre berufen, und was viel mit dem Drohnenkrieg gemein hat: Exterritorialität. Wer von woanders handelt, dem kann man am Tatort nicht habhaft werden. Mit anderen Worten: Wenn der junge Skinhead am Joystick auf einem amerikanischen Stützpunkt in Stuttgart sitzt und eine Hochzeitsgesellschaft in Pakistan auslöschen lässt, tut er das zwar auf amerikanischem Hoheitsgebiet, auf das Deutsche keinen Zugriff haben, handelt im Auftrag der USA und braucht von ihr keine Strafverfolgung fürchten und tötet – was in allen drei Ländern völker- und strafrechtswidrig wäre – Zivilisten, die kurzerhand zu Kombattanten also feindlichen Kriegern erklärt werde. Unsere Daten werden auf Übersee abgeschöpft, oder durch unsere eigenen Dienste. Die tun das offensichtlich weil ausweislich der ausbleibenden Reaktion unter Duldung oder (bei unseren Diensten) auf Veranlassung der jeweils amtierenden Bundesregierung. Sie greifen in die Informationsfreiheit ein, in die Vertraulichkeit der Kommunikation, sie verletzen das Briefgeheimnis und das alles dank der systemimmanenten Internationalität auf Niemandsland. Mag sein das viel auch in den USA abgeschöpft wird, aber zwischen zwei Geräten kann manchmal eine Kontinentalgrenze liegen, und da sind die Daten per se international. Das ist illegal, Merkel verletzt ihr legal agreement mit den Deutschen (vulgo: Amtseid) und vielen ist es scheißegal, und dazu tragen Beiträge wie dieser bei, die Unternehmen und ihre (Sehn-)Sucht nach Daten mit illegalen Machenschaften gleichzusetzen.
Ist nur bei mir hier die Schrift ein Grau auf Weis? Das ist der Lesbarkeit, zumindest bei mir, nicht gerade zuträglich.
Wer versucht, das Tracking der FAZ (das auch nicht gutzuheißen ist) mit der Überwachung der NSA zu vergleichen, der hat den Skandal nicht ansatzweise verstanden.
Verlage sind Wirtschaftsunternehmen, wer hier eine gesteigerte Moral voraussetzt, ist naiv. Haber hier gibt es einigermaßen Richtlinien und Gesetze. Außerdem kann ich als User das Tracken jederzeit unterbinden.
Die Totalüberwachung kann man als User nicht unterbinden.
Und vielleicht liegt das fehlende Verständnis für den Skandal auch bei Vögeln, wie dem Blogger hier, die mit dem großen Zeigefinger klugscheißen und dabei die Tatsachen verdrehen..
Facebook als praktisch trackingfreie Zone zu beschreiben, ist nicht spitzfindig, sondern schlicht falsch und grob verzerrend. Denn Facebook IST ein einziger großer Tracking-Dienst, der nicht nur erfasst, was ich auf Facebook.com treibe, sondern dank eingebundener Like-Buttons und Kommentarspalten auch in einem erklecklichen Anteil des “wilden” Internets. Wenn man dann noch berücksichtigt, dass Facebook diese Tracking-Daten mit dem Abbild meiner Sozialstruktur, Metadaten, Nachrichtenverkehr und Interessen verknüpft, wie sie sich aus meinen Facebook-Stammdaten ergibt, so ist das Tracking durch Optimizely & Co auf Faz.Net und Konsorten zwar auch nicht besonders toll, aber doch ein vielfach kleineres Kaliber. Abgesehen davon: gegen das Tracking auf den genannten Nachrichtenseiten durch die genannten Trackingdienste schützt mich Ghostry ganz passabel. Aber was schützt mich von Tracking durch Facebook auf Facebook?
Natürlich ist es ein Unterschied, ob ein Geheimdienst Daten sammelt (ob sie tatsächlich alle verwertet werden bzw. verwertet werden können, müsste man ja noch prüfen) oder die FAZ Tracking-Dienste auf der Seite einbindet. Was mich aber tatsächlich stört, ist die Heuchelei, die da im Rahmen der Unwissenheit der meisten User betrieben wird, sobald es gegen die “bösen Firmen” Amazon und Google geht. Auch hier gilt nämlich: Niemand muss sie nutzen; es besteht keine Verpflichtung dazu. Aber bisher ist noch jedes Anti-Amazon-Buch bei Amazon käuflich zu erwerben.
Es stimmt, dass kaum eine Website für die Leser transparent macht, wie sie Tracking-Dienste nutzt. Das ist problematisch und schade, liegt aber daran, wie Verlage und Redaktionen funktionieren. Trotzdem bezweifle ich ganz stark, dass aus der Verbreitung von Tracking-Diensten ein Zusammenhang mit der ausbleibenden Empörung gegen die NSA-Affäre abzuleiten ist. Welcher durchschnittliche Internetnutzer, als Beispiel sei meine Mutter genannt, weiß schon von Programmen wie Ghostery oder beschäftigt sich damit, welche Website welchen Tracking-Dienst nutzt? Die meisten wissen vermutlich nicht einmal, was Tracking-Dienste überhaupt sind. Das Argument, die fehlende Empörung lasse sich davon ableiten, impliziert jedoch, dass dieses Vorgehen der Masse bekannt ist. Sicher: Ich finde es auch problematisch, wie Tracking-Dienste arbeiten und nutze eben deshalb Dienste wie Ghostery. Aber andererseits finanzieren sich Onlinenachrichten so heute (noch). Und würden diese Einnahmen wegfallen, gäbe es weniger festangestellte Journalisten, die über die NSA-Affäre berichten könnten und die Aufmerksamkeit für das ganze Thema wäre noch geringer. Und das können wir ja alle auch nicht wollen, oder?
In der Regel knacken Verlage, Redaktionen und Journalisten aktiv keine Mails, präparieren Websites oder arbeiten mit anderen geheimdienstlichen Methoden. Trackingdaten und ähnliches zu erheben, ist grundsätzlich legitim, zudem kann man Trackingdienste abschalten.
http://mobile.theverge.com/2013/12/10/5198592/nsa-reportedly-piggybacking-on-google-advertising-cookies
Du hast verstanden, dass die Daten, die hier anfallen, von Facebook auch geloggt werden (nur eben lokal) und dann eben im Anschluss weiterverkauft werden, statt sie für wenig Geld direkt und für jeden sichtbar (und für jeden unterbindbar) weiterzuleiten?
Kannst du hierzu erklären, wie du das genau meinst?
Der Vergleich mit Facebook hinkt wirklich sehr. Auf der Webseite von DoubleClick befinden sich auch keine (externen) Tracking-Cookies 😉
Ist ja verschiedentlich in den Kommentaren schon angeklungen – ich finde es wirklich naiv die These aufzustellen es gäbe einen Zusammenhang von Impact des Trackings und Anzahl der Tracking-Cookies auf einer Website. Man merkt die Absurdität dieser These bei dem Kommentar zu Facebook. Tatsächlich ist der Zusammenhang eher andersherum: Wenn wenige Tracker viele Daten sammeln und diese ggf. sogar einen Personenbezug haben dann ist der Impact viel höher als wenn ein Flohzirkus von Trackern hier und dort ein Krümel abspeichern und überdies keinen Schimmer haben wen sie da tracken. Die Datenschützer sprechen in den Zusammenhang sogar von informationeller Gewaltenteilung, d.h. wenn die Datensammlung auf mehrere Einheiten verteilt ist die untereinander nicht vernetzt sind _erhöht_ das den Datenschutz und nicht umgekehrt.
Davon abgesehen habe ich vor kurzem eine eigene These aufgestellt warum sich niemand in der breiten Öffentlichkeit so richtig über NSA&Co aufregt: http://www.beimnollar.de/2013/09/29/ganz-einfache-these-warum-nsa-fur-viele-kein-skandal-ist/
Mir gefällt der Artikel nicht! Er suggeriert, dass Facebook “nicht so schlimm” wär. Dabei ist Facebook am schlimmsten!
Facebook setzt zwar nicht auf der eigenen Seite Cookies (das stimmt), aber auf allen anderen großen und bekannten Webseiten. Blockt man das Setzen der Cookies *nicht* und loggt sich dann bei Facebook ein, weiß Facebook ganz genau (!), welche Seiten man vorher (und nachher) angesurft hat. Auf Basis dieser Nuterdaten kann dann ein wunderbares Persönlichkeitsprofil mit entsprechenden Empfehlungen erstellt werden. Vorschläge zum gestrigen Kino-Abend, zum Kauf der neuen Schuhe oder vielleicht nach dem Anmelden bei einer Partnerbörse?
Ich finde das vieeel heftiger als FAZ etc., die das wenigstens offen legen.
Hat der Autor gerade “Ghostery” entdeckt und teilt nun den Lesern erstaunt mit, was die schon lange wissen (und nutzen: die 4 Verfolger auf dieser Seite hier sind bei mir natürlich automatisch durchgestrichen, also geblockt).
Danke auf eine gesonderte Herausstellung dieser Tatsache warte ich schon lange.
Leider fehlt eine schlüssige Begründung warum diese Trackingdienste eine Gefahr darstellen können. Eine detaillierte Analyse von einem technischen Standpunkt aus wäre ebenfalls wünschenswert. Nur zu sagen die haben 10, der 14 Trackingdienste usw. reicht nicht.
Ghostery findet auch auf dieser Seite 3 tracker…
Sie könnte ja wenigstens drauf hinweisen mh?
4 Tracker. Next.
Hallo, “ist ja gar nicht so schlimm”-Fraktion.
Ja, euch meine ich.
Ihr, die ihr Kommentare hinterlasst wie “wenigstens cracken die keine Verschlüsselung”, “Falsche Gleichsetzung!1!11!”, “Nicht in den gleichen Topf werfen”, “Verharmloser!1!!”. Hab euch lange nicht gesehen, seid dem die “ich hab nichts zu verbergen!”-Masche nicht mehr ganz so gut zieht. Habt ihr gerade mal geschaut, wie viele Tracker ihr auf euren Blogs habt und seid nun in Verteidigungshaltung? Oder wie soll man das sonst verstehen, dass ihr tracker von irgendwelchen Ad-Networks verteidigt, bei denen ihr keinen blassen Dunst habt, wer alles Zugriff drauf hat, wer welche Daten kreuzreferenziert und wer ein genaues surfprofil von euch baut?
Interessanter Artikel.
Stimme Sven und Anderen zu: es handelt sich hierbei um Angebote mit Opt-Out Option, sei es über über Plugins, Browser Optionen, oder sonstige Filter. Natürlich sollte das Ganze für Nutzer viel transparenter und einfacher werden.
Bei der Überwachungsaffäre kann ich beim besten Willen kein Opt-Out erkennen. Privacy Bit anyone?
Wie wäre es damit Piwik statt Google Analytics einzusetzen? Dann bleiben die Statistiken wenigstens beim Betreiber.
Wer sich im Internet immer noch ohne NoScript rumtreibt, dem ist nicht zu helfen.
Vor dem NSA-Skandal hatte ich mir gesagt: sollen sie mich tracken und Werbung einblenden – irgendwer muss die Websites ja finanzieren. Allerdings hatte ich den Browser so konfiguriert, dass alle Cookies und sonstige gespeicherte Inhalte beim Beenden des Browsers gelöscht werden.
Nach Snowden ist NoScript defaultmäßig ohne jede Ausnahme aktiv: Das nervt zwar etwas, wenn Seiten ohne JavaScript nicht funktionieren, aber dafür sieht man so nebenbei, wer einen alles tracken möchte (Facebook ist übrigens auch meist dabei).
Wenn schon ehrlich, dann richtig. Die Google Webfonts auf dieser Seite lassen sich auch zum tracking nutzen. Und wenn das geht, wirds gemacht.
Netter Tipp. Ich habe eben Ghostery installiert und finde, dass auf dieser Seite 5 Tracker laufen. Nicht gut.
hab seit einige Zeit ebenfalls Ghostery & Noscript im Einsatz und mein bisheriger Spitzenreiter ist die Suedeutsche. da warens auch so um 30.. ebnfalls auch noch lustigerweise bei nem Artikel zu dem Thema..
Agathe hat völlig recht. Erstens ist das Grundprinzip das gleiche, dass man jemanden ausspioniert, gegen seinen Willen und was die meisten Nutzer angeht ohne ihr Wissen oder Möglichkeit sich dagegen zu wehren. Zweitens ist die Differenzierung unmöglich, wo die Daten schließlich landen, denn Daten, die US-Unternehmen und nicht nur die einsammeln, landen ohne Probleme bei Geheimdiensten, teils ohne Wissen der Unternehmen, teils durch aktive Mitarbeit. Es wurde ja sogar dokumentiert, dass Bundesliga-Tracker wie Google die NSA im Umgang mit Riesendatenmengen schulen! Die Interessen sind die gleichen, die Branche auch und man hilft sich eben gegenseitig.
Es interessiert auch nicht, ob Firmen wie Google oder Facebook oder etracker oder Geheimdienste wie die NSA alles über mich wissen, es reicht, dass irgendwer irgendwo diese ungeheure Macht aufbaut. Keiner kann nachvollziehen, ob dieses Wissen nicht schon längst gegen ihn verwendet wird, die sind natürlich nicht doof, das wird so gemacht, dass ihr möglichst nichts davon mitkriegt. Und Ghostery ist keine Versicherung, dass ihr alle Angriffe mitbekommt, es gibt genügend andere Techniken.
Wer hier meint, halb so wild, ist ja nur ne Zeitung mit 10 Trackern am Start, hat schon verloren, denn dann lässt sich gegen die Hardcorespione nicht mehr argumentieren. Sobald die Schnüffeldaten nicht im Haus bleiben, ist was faul. Und selbst dann (piwik) ist es fragwürdig, denn die erschlichenen Daten müssen geschützt werden. Wer Datenschutz so leichtfertig abtut, dass er tracker einsetzt, geht auch ansonsten sorglos mit Nutzerdaten um.
Übrigens fehlt bei der ganzen Diskussion immer wieder der Hinweis auf die Online-Zahlungsdienstleister, Paypal, Visa etc, sowie die Kaufmannsläden Amazon und Ebay. Was die selbst ohne Tracker an Daten einsammeln, kann locker mit Google mithalten, denn wofür ich bereit bin Geld auszugeben, das hat mehr Gewicht als irgendwelche wahllosen Klicks im Netz. Wieviel, für was, wann, wie oft, bei wem.
Nur weil Facebook keine der bekannten externen Adserver-Tracker einsetzt, heißt doch nicht, dass sie keine Daten sammeln und in die USA transferieren !?
Natürlich tun sie das auch! Sie haben nur andere Schnittstellen zu den Werbetreibenden, und es laufen nicht alle Fäden direkt im Browser des Nutzers zusammen.
Hmmm da habe ich doch mal das Plugin installiert und es sagt mir: diese Webseite verwendet Google Analytics …
Könnte vielleicht interessant sein: Es gibt Tracker die mit Reverse-Proxies arbeiten, die werden von Ghostery und Adblock nicht erkannt/geblockt.
Ich weiß von mindestens einer Seite aus diesem Artikel die so getrackt wird und deren Tracker hier nicht gelistet wurde.
Bitte nicht auf haber Strecke mit dem Denken aufhören.
Was wir erleben ist zuerst mal ein exzessiver Wettbewerb von Trackingdiensten. Sie werden immer besser und erhöhen ihre Reichweite ständig. Die Qualität und die Aussagekraft der Daten steigt enorm.
Gleichzeitig werden Daten erst dann wirklich wertvoll, wenn verschiedenartige Sammlungen zusammen geführt werden. Abgesehen vom zwar umfangreichen aber doch eher passiven “alles speichern” macht die NSA genau das. Die rohen Kommunikationsdaten sind anstrengende Daten. Die Trackingdienste leisten hier die Vorarbeit und liefern bewertete Daten.
Hab diesen Artikel zu http://sensiblochamaeleon.blogspot.com/2013/12/wie-tickt-facebook-so-jetzt-sortier-mal.html hinzugefügt, einer aus group discussing fb design&privacy https://www.facebook.com/groups/323441564697/ extrahierten Sammlung von Links zur Facebookstruktur der letzten 3 Jahre. Die Tracker repräsentieren von außen, was die Quantified-Self-Selbstvermarktung von innen tut http://de.wikipedia.org/wiki/Quantified_Self , wenn im lustigen SocialMedia-Casino ( schön verdeutlicht von https://datadealer.com/ ) ein Abbild des produktoptimierten Selbst möglichst attraktiv für den Social-Media-Markt innerhalb von Lobbyisten algorithmisierten, an sich aber rein mathematisch-binären Regeln der allgemein akzeptierten Aufmerksamkeitsökonomie angeboten wird. Social Metrics wie Klout treiben eine derartige Vermessung auf Kosten des Datenschutzes auf die Spitze http://sensiblochamaeleon.wordpress.com/2012/09/05/mit-dem-bedurfnis-nach-mehr-einflus-in-die-klout-falle/ . Interessant sind die Einblendungen auf diversen Seiten “Wir sehen, du benutzt einen Adblocker, bitten dich aber, diesen auszuschalten” . Wann werden Botschaften à la “Bitte schalte doch deine Skriptblocker oder sonstwas ab” erscheinen? – Daß der FB-Code, also auch die Frage, ob da getrackt wird, für Unkundige fast undurchschaubar komplex sein kann, bemerkte ich nach dem Ausdrucken eines einzelnen FB-Skripts aus dem Seitenquelltext “/*id-nr,id-nr*/if(self.CavalryLogger)(…)” mit 43 kompakt gefüllten DIN A4 Seiten Code! – Was in den Wellen von oberflächlichen Skandalmeldungen zu Abhörwahn und Überwachung in den letzten Monaten zu kurz kam, war die Wiederherstellung der korrekten Prioritäten in der Gewichtung von einerseits in der Vermißtensuche oder Verbrechensaufklärung manchmal unvermeidbarem Privatsphäreneingriff zum andererseits Erhalt von Grundpfeilern der Demokratie wie zB Fernmeldegeheimnis § 88 Abs. 1 Telekommunikationsgesetz, Postgeheimnis Art. 10 Abs. 1 Grundgesetz, Persönlichkeitsrecht Art. 2 Abs. 1 i.V.m. Art. 1 Abs. 1 GG, Unverletzlichkeit der Wohnung Art. 13 GG, Unschuldsvermutung Art. 11 Abs. 1 der Allgemeinen Erklärung der Menschenrechte , StGB §201 bis §206 , http://dejure.org/cgi-bin/suche?Suchenach=datenschutz . Wie verzerrt die Prioritäten teilweise sind, zeigen die Infografiken in http://gutjahr.biz/2013/04/bestandsdatenauskunft/ . https://www.facebook.com/about/government_requests spricht da eine harmlosere Sprache.
Ich kann dem Fazit an vielen Stellen zustimmen. Das Problem entsteht, weil erstens die Produktion von journalistischen Vollangeboten Geld kostet und weil zweitens dieses Geld auf der anderen Seite irgendwie eingenommen werden muss. Das ist keine freie Entscheidung der Medien, sondern ergibt sich aus der kapitalistischen Natur unserer Gesellschaft. Im Hausblog der taz schrieb ich mal:
“Am tollsten fänden wir bei der taz es ja, wenn man eine Zeitung einfach machen könnte, ohne dafür Geld ausgeben zu müssen. Aber leider ist so eine Zeitung echt ziemlich teuer: 24,3 Millionen Euro haben dafür im Jahr 2009 bezahlt. Allein unsere drei Druckereien (…) Wenn taz-Produktion nun aber schon so viel Geld kostet, dann wäre es uns am liebsten, dieses Geld wäre einfach da. Etwa durch eine überraschende Erbschaft in vielfacher Millionenhöhe oder weil es durch einen unentdeckten Überweisungsfehler auf unserem Konto gelandet ist oder weil es vom Himmel gefallen ist, manchmal passieren ja die seltsamsten Sachen. Aber weil keiner dieser Fälle bisher eingetreten ist, müssen wir dieses Geld von woanders bekommen. Derzeit sind wir von folgenden Quellen finanziell abhängig (…)”
Wenn wir schon Geld brauchen, dann nehmen wir es natürlich am liebsten von unseren Lesern. Bei der Druck-Ausgabe klappt das ganz gut. Die Kosten werden zu 90 Prozent von den Lesern über Abos und den Kauf einzelner Ausgaben am Kiosk getragen und zu 10 Prozent über die Anzeigen von Unternehmen. Auf die Frage, ob die taz in ihrer Print-Ausgabe auf Anzeigen verzichten könnte, schrieb ich daher mal: “Oh ja. Die taz würde das – anders als viele Zeitungen – überleben, weil Werbung eben nur einen relativ kleinen Anteil reinbringt. Dennoch müssten wir dann unsere Ausgaben kürzen. ”
Online sieht das anders aus. Die taz hatte im Jahr 2011 mal die Kosten für taz.de mit 600.000 Euro veranschlagt. Inzwischen ist es wohl mehr, aber rechnen wir einfach mal mit der Zahl herum. Unsere Leser haben im Jahr 2013 für taz.de 125.000 Euro bezahlt. So kommen also gerade mal 20 Prozent der oben genannten Kosten rein.
Der Verkauf von Werbung auf taz.de brachte uns im 303.473 Euro im Jahr 2012. So kommen immerhin 50 Prozent der Kosten rein.
Die übrigen 30 Prozent der Ausgaben sind nicht durch Einnahmen gedeckt. Dieser Verlust von taz.de wird quersubventioniert durch die gedruckte Ausgabe.
So lange die Zahlungen unserer Leser für taz.de nur einen Bruchteil der Kosten ausmachen, können wir das Angebot nur mit zusätzlichen Anzeigeneinnahmen aufrechterhalten.
Bei den Anzeigeneinnahmen gibt es einen entscheidenden Unterschied zwischen Print und Online. In der gedruckten Ausgabe wird jede Anzeige von uns individuell angenommen. Wir haben uns entschieden, keine Anzeigen mit sexistischem, rassistischem und kriegsverherrlichendem Inhalt abzudrucken. Das ist zugegebenermaßen in der Realität nicht sonderlich relevant, weil Sexisten, Rassisten und Kriegstreiber bei uns gar keine Anzeigen schalten wollen – aber immerhin könnten wir das verhindern. Online-Anzeigen dagegen werden meist nicht individuell beauftragt, weil weil der Aufwand angesichts der geringen Preise für die einzelnen Anzeigenschaltungen zu groß wäre. Stattdessen werden die Anzeigen über Vermarktungsnetzwerke wie Adscale oder AdJug vermittelt und so kommen auch die dort üblichen Anzeigen mit Trackern auf taz.de.
Die taz setzt auch selber Tracker ein, um zu sehen, auf welchen Wegen unsere Leser über die Seite surfen, welche Elemente sie wahrnehmen und welche nicht. Mit den Daten verbessern wir die Darstellung und Aufteilung der Inhalte auf taz.de. Wir nutzen dafür aus Datenschutzgründen nicht den weitverbreiteten Dienst GoogleAnalytics, obwohl er für uns kostenlos wäre, sondern zahlen stattdessen für die Software “etracker”, die konform mit den deutschen Datenschutzbestimmungen ist.
Wir setzen die Tracker nicht “stillschweigend” ein, sondern informieren unsere Leser über die auf taz.de eingesetzen Trackingdienste und empfehlen dort auch Ghostery für die Leser, die diese Tracker selbst nachvollziehen und blocken wollen.
Bleibt nur noch eine Frage: Wie sollte man als Journalist in der redaktionellen Berichterstattung damit umgehen, dass man in einem Verlag arbeitet, der angesichts seiner Existenz in einer kapitalistischen Gesellschaft zu solchen Mitteln des Geldverdienens greift?
Die eine Möglichkeit ist, sich mit seinem Verlag gemein zu machen und nichts zu schreiben, durch das man das Geschäftsgebahren des eigenen Arbeitgebers in Frage stellt. Der Vorteil ist, dass das konsequent ist. Für die Leser entsteht kein “Bruch, den ich so nur belächeln kann”. Der Nachteil ist, dass das dann mit Journalismus nichts mehr zu tun hat.
Die andere Möglichkeit ist, es so zu machen wie die im Blogpost angeführten Beispiele.
Mein Blog zum Thema:
http://text030.wordpress.com/2013/10/30/die-gesellschaft-im-zeitalter-von-stasi-3-0/
Naja,
also Facebook hat halt ein eigenes BI-Tool im Einsatz – die brauchen keine externen Tracker, wie bspw. SZ oder so, denn deren Kernkompetenz its dsa Verfassen von Artikeln, nicht das Entwickeln von BI-Tools für Klickanalyses 🙂
FB sieht durch die eigenen Trackingmechanismen deutlich mehr, als 30 ext. Trackere.
Bei den Zeitungen wird ja nu getrackt, wann was gelesen wurde, also relativ triviale Informationen…
Grüße,
Flo
Leala UG